嵌入式硬件
缩位求和
无穷级数
查询慢
jstl
最短路
JWT
模型蒸馏
xss
数值计算
指针
监控
reactjs
统一认证
ECDSA
高校失物招领系统
次世代建模
SAP调试归档任务
企业应用
dpdk
shuffle
2024/4/13 7:16:52
尚硅谷大数据技术Spark教程-笔记07【Spark内核源码(环境准备、通信环境、应用程序执行、shuffle、内存管理)】
尚硅谷大数据技术-教程-学习路线-笔记汇总表【课程资料下载】视频地址:尚硅谷大数据Spark教程从入门到精通_哔哩哔哩_bilibili 尚硅谷大数据技术Spark教程-笔记01【SparkCore(概述、快速上手、运行环境、运行架构)】尚硅谷大数据技术Spark教程…

MapReduce-shuffle详解
MapReduce-shuffle详解shuffle粗解为什么MapReduce计算模型需要Shuffle过程?Shuffle过程:map端:(Spill过程:包括输出,分区,排序,溢写,合并等)Reduce端&#x…

Stable Diffusion 绘画入门教程(webui)-ControlNet(Shuffle)
Shuffle(随机洗牌),这个预处理器会把参考图的颜色打乱搅拌到一起,然后重新组合的方式重新生成一张图,可以想象出来这是一个整体风格控制的处理器。
那么问题来了,官方为啥会设计个这样的处理器呢,主要是给懒人用的&am…
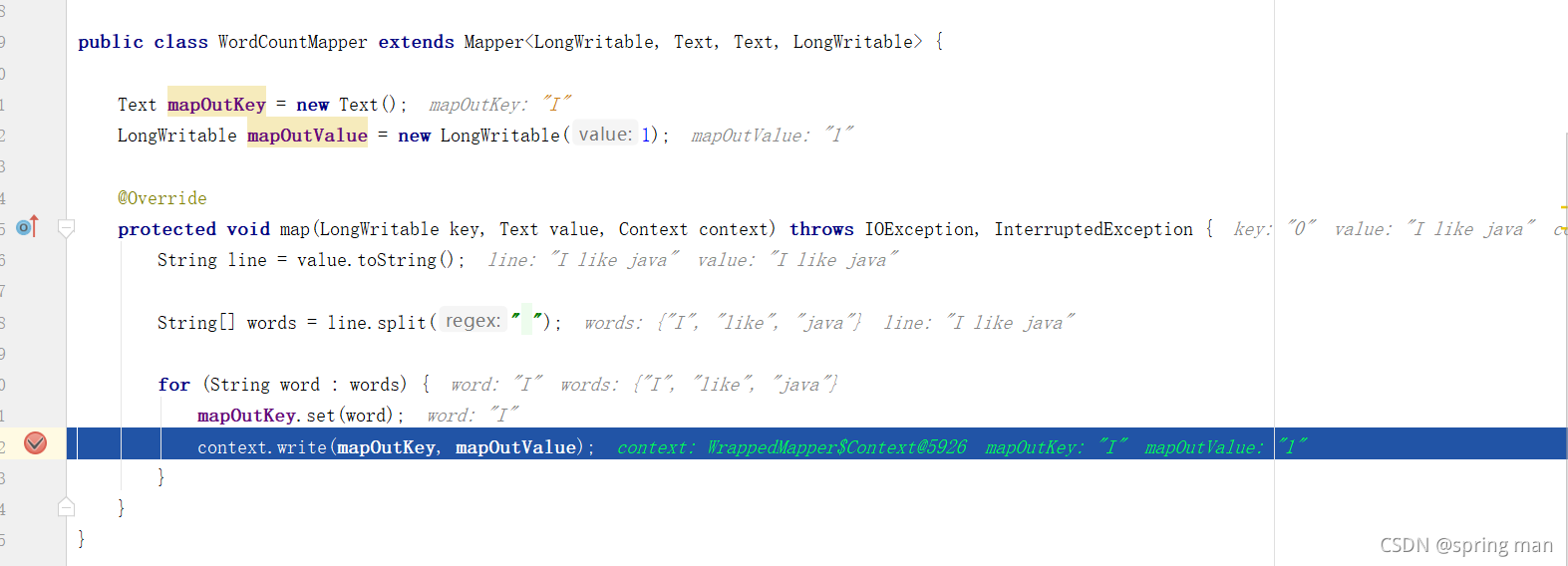
MapReduce之Map阶段
MapReduce阶段分为map,shuffle,reduce。
map进行数据的映射,就是数据结构的转换,shuffle是一种内存缓冲,同时对map后的数据分区、排序。reduce则是最后的聚合。
此文探讨map阶段的主要工作。 map的工作代码介绍split…

Hadoop之MapReduce工作原理
Map阶段
①输入分片(inputsplit),这个时候也就是输入数据的时候,这时会进行会通过内部计算对数据进行逻辑上的分片。默认情况下这里的分片与HDFS中文件的分块是一致的。每一个逻辑上的分片也就对应着一个mapper任务。
②Mapper将…
![[转载]详细探究Spark的shuffle实现](https://img-blog.csdn.net/20160725154513678)
[转载]详细探究Spark的shuffle实现
转载自 http://jerryshao.me/architecture/2014/01/04/spark-shuffle-detail-investigation/
Background
在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性能高低直接影…

MapReduce之Shuffle
承接上文MapReduce之Map阶段。
我们需要将map后的数据往外写。 shuffle收集数据排序和溢写合并收集数据
我们写出的数据是("I", 1)。 我们需要往kvbuffer中写key和value。
写key的时候我们既要写I,又要写它的位置,不然怎么能找到它呢&#…


Spark中宽依赖、shuffle、join之间的关系
这是一个有意思的问题。
准确来说只有宽依赖>shuffle,也就是如果发生了宽依赖那么就一定发生了shuffle过程。其余的都没有直接联系。
1.发生宽依赖就一定会伴随着shuffle。
2.发生shuffle不一定产生宽依赖
比如一个RDD在不断的做join的过程。这个过程中每个R…

Spark Exchange节点和Partitioning
Exchange
在explain时,常看到Exchange节点,这个节点其实就是发生了数据交换 此图片来自于网络截取 BroadcastExchangeExec 主要是用来广播的
ShuffleExchangeExec 里面决定了数据分布的方式和采用哪种shuffle 在这里可以看到好几种不同的分区器 shuf…
MapReduce:Combiner与Shuffle阶段之Reducer输入
目录
Combiner
Reducer的输入
过程概述
源码分析
ReduceTask总览
数据抓取
合并排序 Combiner
网络I/O会限制MR作业的数量,因此尽量避免mapper和reducer任务之间的数据传输是有利的。在之前Shuffle阶段之Mapper输入中可以看到,会调用两次Combine…

Spark系列修炼---入门笔记28
核心内容: 1、Spark的Shuffle机制 Shuffle是什么? Shuffle中文翻译为“洗牌”,需要Shuffle的关键性原因是某种具有共同特征的数据需要最终汇聚到一个计算节点上进行计算,Shuffle是MapReduce框架中的一个特定的阶段,介…

rdd算子之byKey系列
spark中有一些xxxByKey的算子。我们来看看。 rdd算子之byKey系列groupByKey解释实现groupByreduceByKeydistinctaggregateByKeycombineByKeygroupByKey
解释
假设我们要对一些字符串列表进行分组:
object GroupByKeyOperator {def main(args: Array[String]): Un…
Scala/Java - shuffle 数组详解
一.引言
本地使用 spark paralize 数组 rdd 时需要构造一个随机数组,分别使用 java.util 和 scala.util 实现,下面记录下不同的 shuffle 方法以及踩到的坑。 二.java
1.API 错误版 ❌
java.util.collenctions 提供了 shuffle 的方法,支持将…

MapReduce:shuffle阶段之Mapper输出
shuffle本意为混洗,MR将排完序的mapper输出作为reducer的输入的过程就称为shuffle,可以理解为mapper到reducer的中间过程,在这个过程中MR框架其实干了很多事。 Mapper输出阶段概述
map函数开始产生输出时(调用context.write()方法࿰…