基本方法
搞一张照片,搞一段语音,合成照片和语音,同时让照片中的人物动起来,特别是头、眼睛和嘴。
语音合成
语音合成的方法很多,也比较成熟了,大家可以选择自己方便的,直接录音也可以,只要能生成一个语音文件就行了。
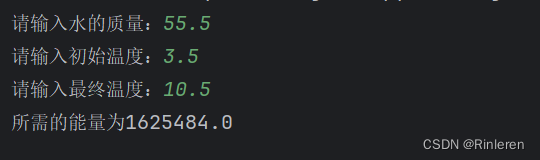
如下图所示 :输入你的文字,选择播音员,填写验证码,点击转换按钮。

生成速度挺快的,然后在左边这里可以试听和下载。

照片生成
这里介绍的方法需要使用比较真实的照片,如果太二次元了,视频人脸的效果会比较差。大家可以使用自己真实的照片,也可以使用Stable Diffusion生成一张,也可以使用图生图稍微改造下自己的照片,总之要尽量真实一些。
另外这张照片尽量正面一些,侧脸生成的视频可能会出现头和身体拼接不太好的情况,所以如果有证件照是最好的。
我这里演示生成一张真实照片,看AI生成的美女都有些厌倦了,今天我们生成个帅哥。
(1)生成工具使用 Stable Diffusion WebUI,模型选择 realisticVisionV20,这个模型生成的图片看起来比较真实。

提示词:best quality, front photo of a young man, chinese, portrait,black t-shirt, short hair, (looking at viewer), Sense of technology, in an office, computers, screen, books, upper body,
反向提示词: easy_negative, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
(2)采样器这里选择DPM++ 2M SDE Karras,选择别的也没问题,只要生成一张人物照片就可以了。
采样步数根据采样器选择,这里是40,建议20-40,以实际出图效果为准。
尺寸这里选择竖版,放到手机里会比较合适。
生成次数:建议先把提示词写好了,然后一次多生成几张,从里边选择最好的,节省时间。

(3)这里我选择一张自认为看起来还不错的图片,把这张图下载下来备用。

视频合成
这是最关键的一步,这里还是使用Stable Diffusion WebUI,不过只是使用其中的一个插件,这个插件的名字就是SadTalker。
SadTalker是Github上开源的,主要成员也都是国内的技术大佬,地址:github.com/OpenTalker/…
这里默认大家都安装好Stable Diffusion WebUI了,如果还没安装过的朋友,建议去AutoDL上租一个服务器体验下,方便不贵,选择A5000规格的就差不多了,安装教程网上应该挺多的,这里就不啰嗦了,还不会的可以联系我。
关于SadTalker插件的安装方法我这里介绍两种。
安装方法一
适合访问Github或者外网比较顺畅的用户,因为需要自动下载很多东西。
在SD WebUI中通过扩展插件页面安装,如下图所示:

这个插件需要下载的文件很多,有的文件还比较大,请耐心等待。如果不确定是不是出问题了,可以看看控制台输出的内容,有没有错误。
安装完了,不要忘了重启Stable Diffusion,要整个重启,不要只重启WebUI。
安装方法二
适合访问外网不太方便的用户,把这个插件需要的文件通过别的方式提前下载好,比如迅雷下载,只要上传到指定的目录就行了。
- 主程序:
放到 stable-diffusion-webui/extensions/SadTalker
github.com/OpenTalker/…
- 视频模型:
放到 stable-diffusion-webui/extensions/SadTalker/checkpoints
github.com/OpenTalker/…
github.com/OpenTalker/…
github.com/OpenTalker/…
github.com/OpenTalker/…
- 修脸模型:
放到 stable-diffusion-webui/extensions/SadTalker/gfpgan/weights 和 stable-diffusion-webui/models/GFPGAN
github.com/xinntao/fac…
github.com/xinntao/fac…
github.com/TencentARC/…
github.com/xinntao/fac…
为了方便使用这种方式部署,我也把相关的文件做了一个打包,大家不用一个一个下载。关注/公/众/号:萤火遛AI,发消息:数字人,即可获得下载地址。
(1)首先把文件下载到本地或者你的云环境,这里以AutoDL为例,我把它放到 /root 目录中。

(2)然后解压文件到 stable diffusion webui的扩展目录,并拷贝几个文件到SD模型目录:
tar -xvf /root/SadTalker.tar -C /root/stable-diffusion-webui/extensions
cp -r /root/stable-diffusion-webui/extensions/SadTalker/gfpgan/weights/* /root/stable-diffusion-webui/models/GFPGAN/
看到下边的结果,就基本上差不多了。
扩展目录下边有这个文件夹:

SD models 目录下有这几个文件:

部署完毕,不要忘了重启。
使用方法
在SD WebUI的Tab菜单中找到SadTalker,按照下边的顺序进行设置。

1、上传人物照片。
2、上传语音文件。
3、选择视频人物的姿势:实际就是人说话时头部的动作,个人感觉有点摇头晃脑,可以使用不同的数字看看。
4、分辨率:512的视频分辨率比256大。
5、图片处理方法:corp是从图片截取头部做视频,resize适合大头照或者证件照,full就是全身照做视频,extcorp和extfull没做细致研究,大家自己对比下。
6、Still Model:让头部不要动作太大,以致偏离身体,负面效果是头不怎么动了。
7、GFPGAN:修脸,说话时嘴和眼的动作可能让脸有些变形,选上他让脸部好看一些。
最后点击“生成”,根据硬件的运行速度和你的勾选设置,可能需要几分钟的时间,耐心等待。
我这里生成的视频(视频太占地,截个图算了):

可能遇到的问题
(1) 启动的时候报错:SadTalker will not support download…

这个错误就是模型下载不下来,告诉我们要去手动下载。
这里有两个方法:
- 执行下边的命令触发下载,注意 cd 之后的路径替换成你自己的SadTalker安装路径:
cd stable-diffusion-webui/extensions/SadTalker
chmod 755 scripts/download_models.sh
scripts/download_models.sh
- 下载所有的模版,然后手工上传到相关目录,上边安装方法二中已经介绍过,可以使用我打包好的文件包。
(2) 合成视频时报错:No module named ‘xxx’

使用 pip install xxx 就可以了,注意如果使用了python虚拟环境,需要先激活它,比如这里要先执行source xxx。
source /root/stable-diffusion-webui/venv/bin/activate
pip install librosa
(3)合成视频时报错:No such file or directory: ‘/tmp/gradio/xxx’,创建目录就可以了:
mkdir -p /tmp/gradio
(4)如果提示找不到 ffmpeg,我这里没遇到,如果出现请先下载安装:ffmpeg.org/download.ht…
以上就是本文的主要内容了,使用这种方法就可以无限制作自己的AI专属数字人,想要什么样的风格都可以,想做多少个都可以,有兴趣的快去试试吧。
注意要遵纪守法,不要搞出事情来。
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。