本文是发表于CVPR 2023上的一篇论文:[2212.04488] Multi-Concept Customization of Text-to-Image Diffusion (arxiv.org)
一、引言
本文主要做的工作是对stable-diffusion的预训练模型进行微调,需要的显存相对较多,论文中测试时是在两块GPU上微调,需要30GB的显存,不过他调的batchsize=8,因为我自己的算力有限,我把复现的时候把batchsize调成了2,然后在两块3090上跑的,至于最低要求多少还没测试,不过个人认为最低也要有一张3090。
在复现前,请自行安装好Python的环境,本文就不叙述了哈哈。
二、下载相关文件及搭建环境
1.下载项目及环境搭建
adobe-research/custom-diffusion: Custom Diffusion: Multi-Concept Customization of Text-to-Image Diffusion (CVPR 2023) (github.com)
上述链接是本文代码的链接,这篇文章的代码实际上是基于Stable-diffusion构建的,所以我的建议是可以先去复现一下stable-diffusion的代码,再来学习这篇文章以及代码。stable-diffusion的复现可以看我另外一篇文章:stable-diffusion复现笔记,当然如果你想直接上手,可以按照项目中readme来构建,这里我默认已经有装过stable-diffusion了哈,因为很多文件都是相同的,如果你是直接上手,有些文件比如sd-v1-4.ckpt的下载等问题,都可以去看我这篇stable-diffusion复现笔记。
git clone https://github.com/adobe-research/custom-diffusion.git
cd custom-diffusion
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
conda env create -f environment.yaml
conda activate ldm
pip install clip-retrieval tqdm 上述是论文给出的环境搭建代码,如果你跟我一样已经做过stable-diffusion的安装,可以直接执行最后一行 pip install clip-retrieval tqdm 。
2.下载数据集
复现的时候我用的是官方给的数据集,下载地址:https://www.cs.cmu.edu/~custom-diffusion/assets/data.zip
三、运行
复现的过程我主要采用以生成的图像作为正则化来实现,方便起见,主要还是按照官方给的示例来复现。
1.单一概念微调——生成的图像作为正则化

第一步:这里我们可以直接执行命令文件,<pretrained-model-path>是预训练模型的路径,如:/data/disk1/sxtang/models/sd-v1-4.ckpt
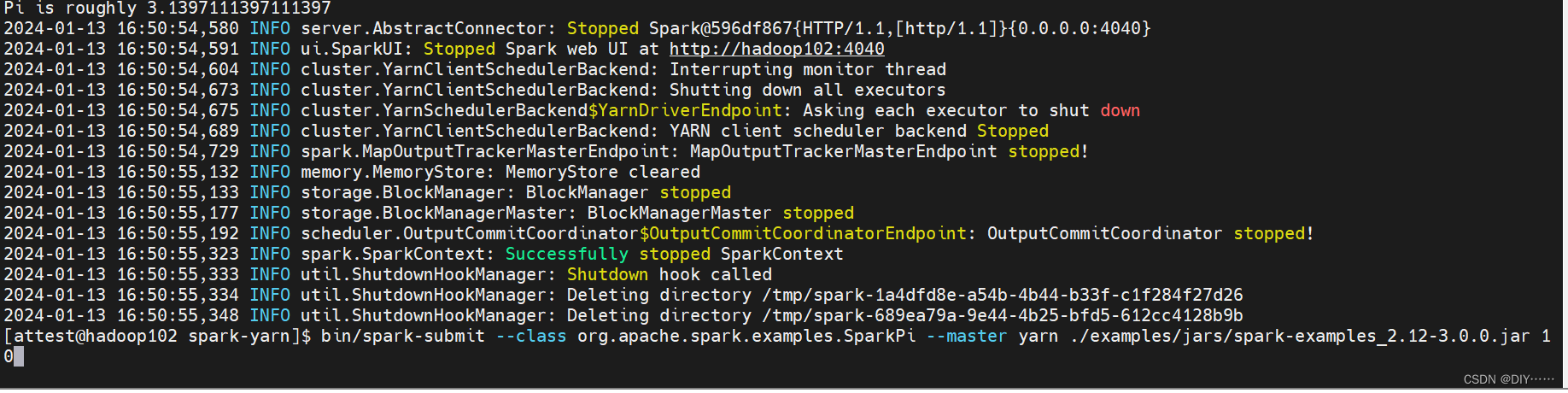
bash scripts/finetune_gen.sh "cat" data/cat gen_reg/samples_cat cat finetune_addtoken.yaml <pretrained-model-path>这个sh文件会执行两个脚本文件:sample.py、train.py。
先执行sample.py生成用于正则化的图像,一共是200张,然后再执行train.py文件对预训练的模型进行微调,如果一切顺利,命令行最后的输入应该如下:

生成的正则化图像的目录:

微调所得模型目录:

复现过程中我所遇到的问题:
(1).我是在RTX3090上进行采样生成图片的,但是如果按照代码中默认的参数去执行,我的显存是不够的(论文毕竟是在两块A100做的),然后我的解决方法是把参数调了一下,改成:
--n_samples 5 --n_iter 40 这里主要还是根据自己的情况去调整,如果还是爆显存的话,可以把数值都调小点,然后多执行几次sample脚本也是可以的。
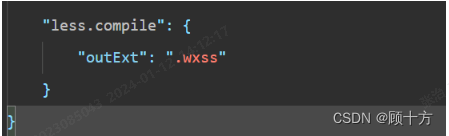
(2).之前也说了,代码默认的batchsize=4,我跑不了哈哈,所以调整一下batchsize的大小。
具体的,在configs/custom-diffusion/finetune_addtoken.yaml文件中更改:

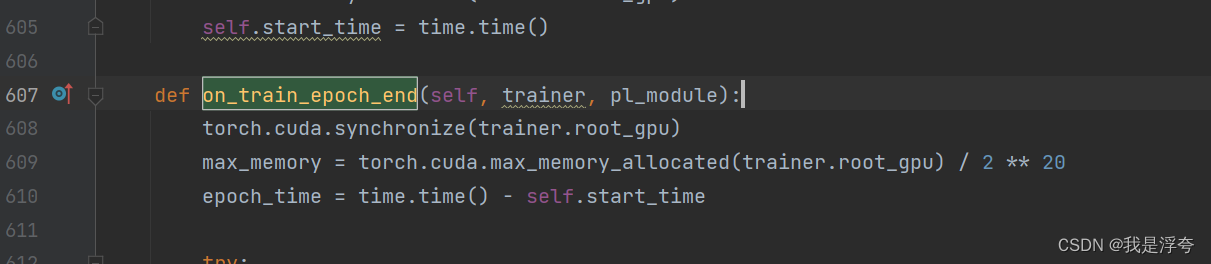
(3).TypeError: CUDACallback.on_train_epoch_end() missing 1 required positional argument: 'outputs'问题。

这里主要是pytorch-lighting的版本问题,需要把这个outputs参数删掉,具体的,在train.py文件下的on_train_epoch_end函数中:
(4).pytorch_lightning.utilities.exceptions.MisconfigurationException: No `test_dataloader()` method defined to run `Trainer.test`.

这里说什么没定义这个方法,解决的方法就是在运行的时候直接加上参数--no-test即可。
第二步:更新权重
执行下面的命令即可实现,这里<folder-name> 就是你微调后的那个模型的文件夹,比如:2024-01-13T14-11-49_cat-sdv4,这一步我在执行过程中没有遇到什么问题。
## save updated model weights
python src/get_deltas.py --path logs/<folder-name> --newtoken 1第三步:运行
## sample
python sample.py --prompt "<new1> cat playing with a ball" --delta_ckpt logs/<folder-name>/checkpoints/delta_epoch\=000004.ckpt --ckpt <pretrained-model-path>
这个new1就是个占位符,无需更改;<folder-name>和上述的含义一样,最后这个“000004.ckpt”是你想要用的权重文件名称。 最后--ckpt <pretrained-model-path> 就是预训练的模型路径。
如果一切顺利的话,就会出图啦!
图片存放的位置以及我生成的图片如下:

2.多概念微调——生成的图像作为正则化

官方的readme中只给出了基于真实图像的代码,所以自己实现了一下生成图像正则化。
第一步:生成正则化图像。
上面我们已经生成的cat的正则化图像,这里还需要wooden_pot的正则化图像,所以我们需要先采样生成图像,我这里用的命令如下:
python -u sample.py \
--n_samples 5 \
--n_iter 40 \
--scale 6 \
--ddim_steps 50 \
--ckpt /data/disk1/sxtang/models/sd-v1-4.ckpt \ #预训练模型的路径
--ddim_eta 1. \
--outdir "gen_reg/samples_wooden_pot" \ # 输出图像的路径
--prompt "photo of a wooden_pot" 第二步:微调,这里我稍微改了一下那个项目中给出的基于真实图像实现的.sh文件
#!/usr/bin/env bash
#### command to run with retrieved images as regularization
# 1st arg: target caption1
# 2nd arg: path to target images1
# 3rd arg: path where retrieved images1 are saved
# 4rth arg: target caption2
# 5th arg: path to target images2
# 6th arg: path where retrieved images2 are saved
# 7th arg: name of the experiment
# 8th arg: config name
# 9th arg: pretrained model path
ARRAY=()
for i in "$@"
do
echo $i
ARRAY+=("${i}")
done
python -u train.py \
--base configs/custom-diffusion/${ARRAY[7]} \
-t --gpus 6,7 \
--resume-from-checkpoint-custom ${ARRAY[8]} \
--caption "<new1> ${ARRAY[0]}" \
--datapath ${ARRAY[1]} \
--reg_datapath "${ARRAY[2]}/samples" \
--reg_caption "${ARRAY[0]}" \
--caption2 "<new2> ${ARRAY[3]}" \
--datapath2 ${ARRAY[4]} \
--reg_datapath2 "${ARRAY[5]}/samples" \
--reg_caption2 "${ARRAY[3]}" \
--modifier_token "<new1>+<new2>" \
--name "${ARRAY[6]}-sdv4"
执行命令:
bash scripts/finetune_joint_gen.sh "wooden pot" data/wooden_pot gen_reg/samples_wooden_pot \
"cat" data/cat gen_reg/samples_cat \
wooden_pot+cat finetune_joint.yaml /data/disk1/sxtang/models/sd-v1-4.ckpt注:如果需要调整如batchsize等参数,这里是在finetune_joint.yaml文件中更改。
如果一切顺利,出现如下界面,就代表着微调成功啦:

后面两步和单个概念那边一样,这里不过多叙述。
第二步:更新权重
## save updated model weights
python src/get_deltas.py --path logs/<folder-name> --newtoken 2第三步:运行
## sample
python sample.py --prompt "the <new2> cat sculpture in the style of a <new1> wooden pot" --delta_ckpt logs/<folder-name>/checkpoints/delta_epoch\=000004.ckpt --ckpt <pretrained-model-path>下面是我测试所生成的图像:

四、最后
这篇文章和Dreambooth等有着异曲同工之妙,都是为了实现个性化的图像生成,当然论文中还有比如通过diffusers实现等功能,如果感兴趣可以自己去试试。