一、Diffusion扩散理论
1.1、 Diffusion Model(扩散模型)
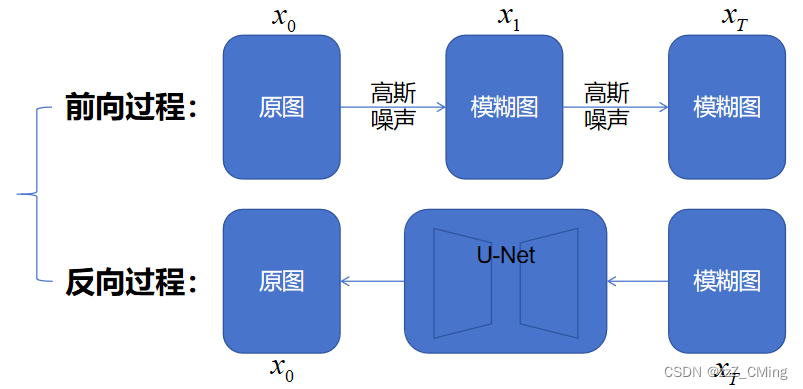
Diffusion扩散模型分为两个阶段:前向过程 + 反向过程
- 前向过程:不断往输入图片中添加高斯噪声来破坏图像
- 反向过程:使用一系列马尔可夫链逐步将噪声还原为原始图片
前向过程 ——>图片中添加噪声
反向过程——>去除图片中的噪声
1.2、 训练过程:U-Net网络
在每一轮的训练过程中,包含以下内容:
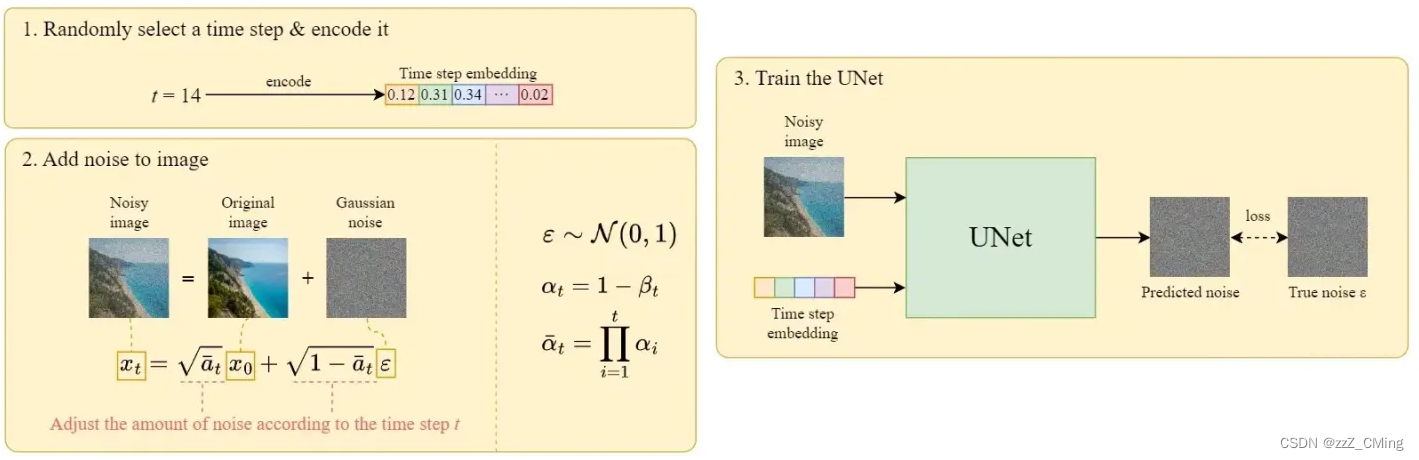
- 每一个训练样本对应一个随机时刻向量time step,编码时刻向量t转化为对应的time step Embedding向量;
- 将时刻向量t对应的高斯噪声ε应用到图片中,得到噪声图Noisy image;
- 将成组的time step Embedding向量、Noisy image注入到U-Net训练;
- U-Net输出预测噪声Predicted noise,与真实高斯噪声True noise ε,构建损失。
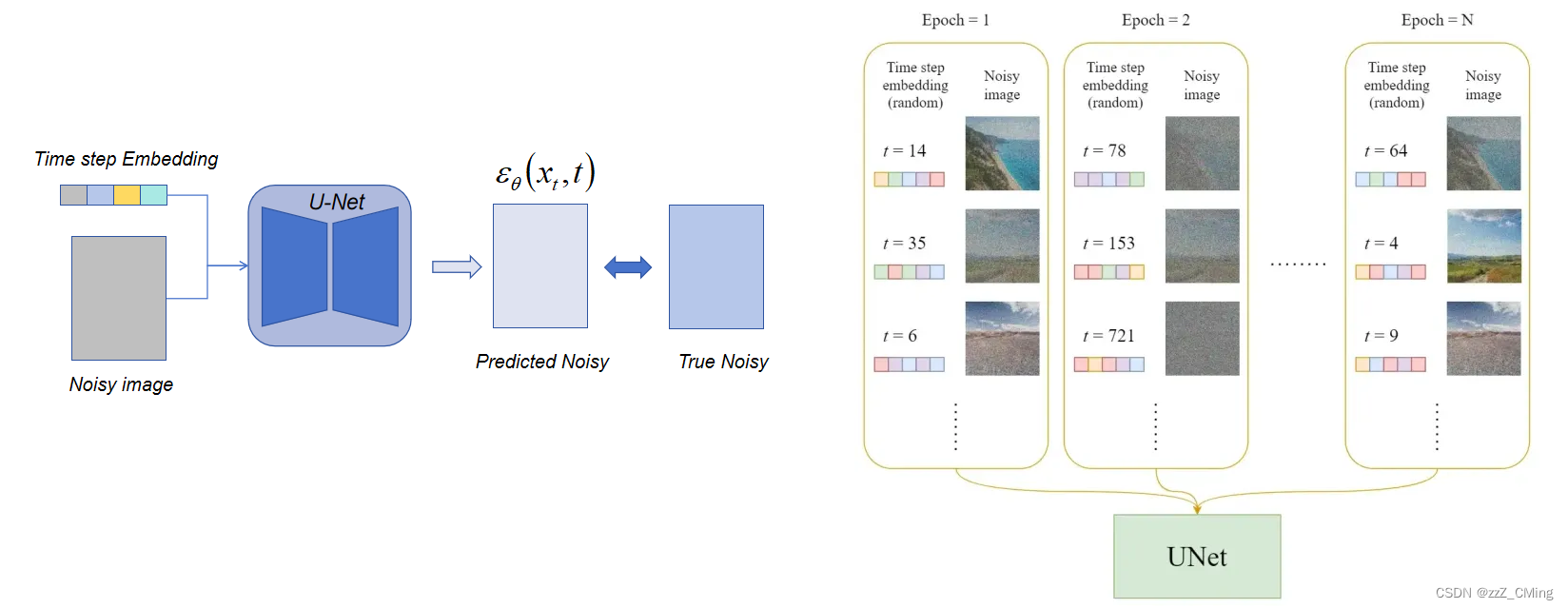
下图是每个Epoch详细的训练过程:

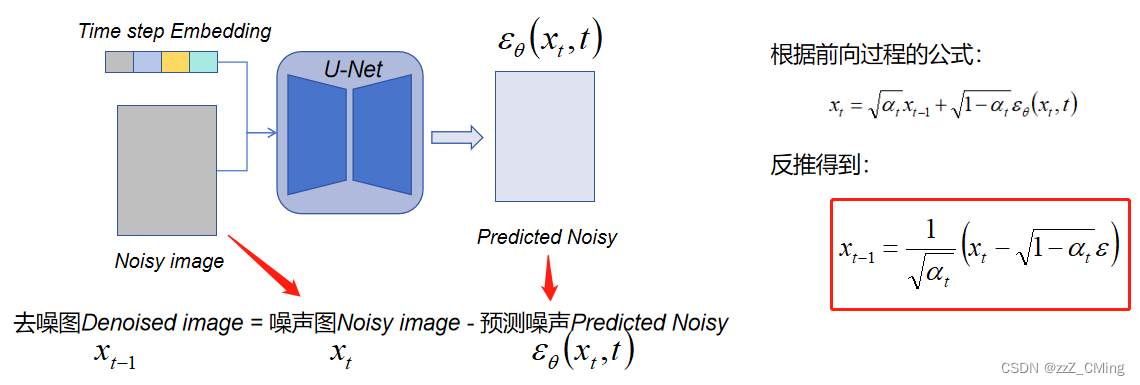
1.3、 推理过程:反向扩散
噪声图Noisy image经过训练后的U-Net网络,会得到预测噪声Predicted Noisy,而:去噪图Denoised image = 噪声图Noisy image - 预测噪声图Predicted Noisy。(计算公式省略了具体的参数,只表述逻辑关系)
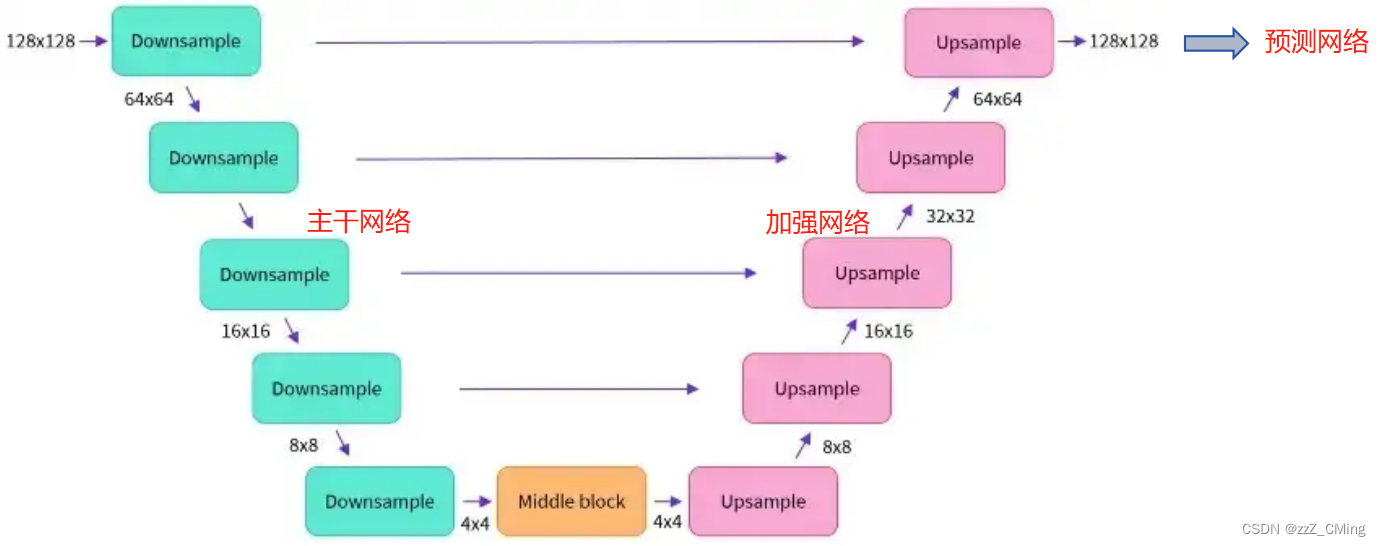
1.4、 补充:U-Net结构
U-Net的模型结构就是一个编-解码的过程,下采样Downsample、中间块Middle block、上采样Upsample中都包含了ResNet残差网络
1、主干网络做特征提取;2、加强网络做特征组合;3、预测网络做预测输出;
1.5、补充:DM扩散模型的缺点
- Diffusion Model是在原图上完成前向过程、反向过程,计算量巨大;
- Diffusion Model只与时刻向量t产生作用,生成的结果不可控;
二、Stable Diffusion原理
为改善DM扩散模型的缺点,Stable Diffusion引入图像压缩技术,在低维空间完成扩散过程;并添加CLIP模型,使文本-图像产生关联。
2.1、Stable Diffusion较Diffusion的改进点
1. 图像压缩:DM扩散模型在原图上进行的操作,而Stale Diffusion是在较低维度的潜在空间上应用扩散过程,而不是使用实际像素空间,这样可以大幅减少内存和计算成本;
2. 文本-图像关联:在反向扩散过程中对U-Net的结构做了修改,使其可以添加文本数据Text Embedding,使得在每一轮的去噪过程中,文本与图像都能产生关联;

2.2、Stable Diffusion的生成过程
Stable Diffusion在实际应用中的过程:原图——经过编码器E变成低维编码图——DM的前向过程逐步变成噪声图——T轮U-net网络完成DM的反向过程——经过解码器D变成新图。
- Stable Diffusion会事先训练好一个编码器E、解码器D,来学习原始图像与低维数据之间的压缩/还原过程;
- 首先通过训练好的编码器E ,将原始图像压缩成低维的Latent data(图像压缩);
- 然后用低维噪声Latent data、时刻向量t、文本向量Text Embedding、在U-Net网络进行T轮去噪,完成扩散过程;
- 最后将得到的低维去噪图通过训练好的解码器D,还原出原始图像,完成整个扩散生成过程。
2.3、补充:文本-图像关联——CLIP模型
2.4、补充:Stable Diffusion训练的四个主流AI模型
- Dreambooth:会使用正则化。通常只用少量图片做输入微调,就可以做一些其他扩散模型不能或者不擅长的事情——具备个性化结果的能力,既包括文本到图像模型生成的结果,也包括用户输入的任何图片;
- text-inversion:通过控制文本到图像的管道,标记特定的单词,在文本提示中使用,以实现对生成图像的细粒度控制;
- LoRA:大型语言模型的低阶自适应,简化过程降低硬件需求;
- Hypernetwork:这是连接到Stable Diffusion模型上的一个小型神经网络,是噪声预测器U-Net的交叉互视(cross-attention)模块;
四个主流模型的区别:
- Dreambooth最直接但非常复杂占内存大,用的人很多评价好;
- text-inversion很聪明,不用重新创作一个新模型,所有人都可以下载并运用到自己的模型,模型小,存储空间占用小;
- LoRA可以在不做完整模型拷贝的情况下,让模型理解这个概念,速度快;
- Hypernetwork:没有官方论文;
三、补充:四大生成模型对比
GAN生成对抗模型、VAE变微分自动编码器、流模型、DM扩散模型
3.1、GAN生成对抗模型
- GAN模型要同时训练两个网络,难度较大,多模态分布学习困难;
- 不容易收敛,不好观察损失;
- 图像特征多样性较差,容易出现模型坍缩,只关注如何骗过判别器;
3.2、VAE变微分自动编码器
Deepfaker、DeepFaceLab的处理方式,生成中间状态
3.3、流模型
待完善