👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦!

🤖 将AI融入CG特效工作流,体验极致的效率提升

BV1pP411r7HY
这是 B站UP主 @特效小哥studio 和 @拓星研究所 联合投稿的一个AI特效短篇「Flower」以及幕后制作花絮。
在前2分钟的特效视频里,一片废土之上,机器人手持一朵紫色的小花,穿越漫长的激流终于来到一片花海,并最终殒身在目的地 (实话说,最后一个镜头还是很震撼的)。

在其后5分钟的视频内,UP主们分享了团队如何只在5天内完成本次制作,以及将哪些AI技术融入了影视制作的工作流。
不同于一般的toy project,这是真正的业内视角,探索人和AI如何更好地配合:
剧本设计。将AI聊天工具引入剧本设计阶段,收集了足够的信息用于片中画面和动作设计
图形设计。以开头的「骷髅头」场景为例,10帧的镜头一般需要特效工作人员5天的时间,但是新建场景并简单建模后使用 Stable Diffusion 进行单独渲染,只需要1个小时(甚至10分钟),极大提升了工作效率
动作捕捉。相较于传统的手K (慢)、惯性动补 (不稳定)、光学动补 (贵),AI视频动捕节省了大量时间和成本
渲染技术。使用了 NVIDIA 的 DLSS3 和 nvidia canvas 等最新技术和软件,加速实时渲染和提升画面质量 ⋙ B站完整视频

🤖 快手App开放「快手AI对话」功能内测,基于「快意 」自研大模型

8月18日,快手App在安卓版本开放内测「快手AI对话」功能,点击搜索首页右上角AI图标即可进入内测首页,输入问题就可以开启对话。
「快手AI对话」依托于站内社区内容生态,可以帮助用户快速查找短视频、达人、百科等内容,还将为用户提供全网检索服务 ⋙ 查看内测详情

快手自研的大语言模型「快意 (KwaiYii)」已经开启内测,并为业务团队提供了标准 API 和定制化项目合作方案,包括上述「快手AI对话」产品。
「快意 (KwaiYii)」是由快手AI团队从零到一独立自主研发的一系列大语言模型,包含多种参数规模,其中新版本 KwaiYii-13B 在多个 Benchmark 上都处于领先水平,证明了其在自然语言处理任务中的出色性能 ⋙ 快意 GitHub
🤖 Midjourney 正式上线局部重绘功能 Vary (Region)
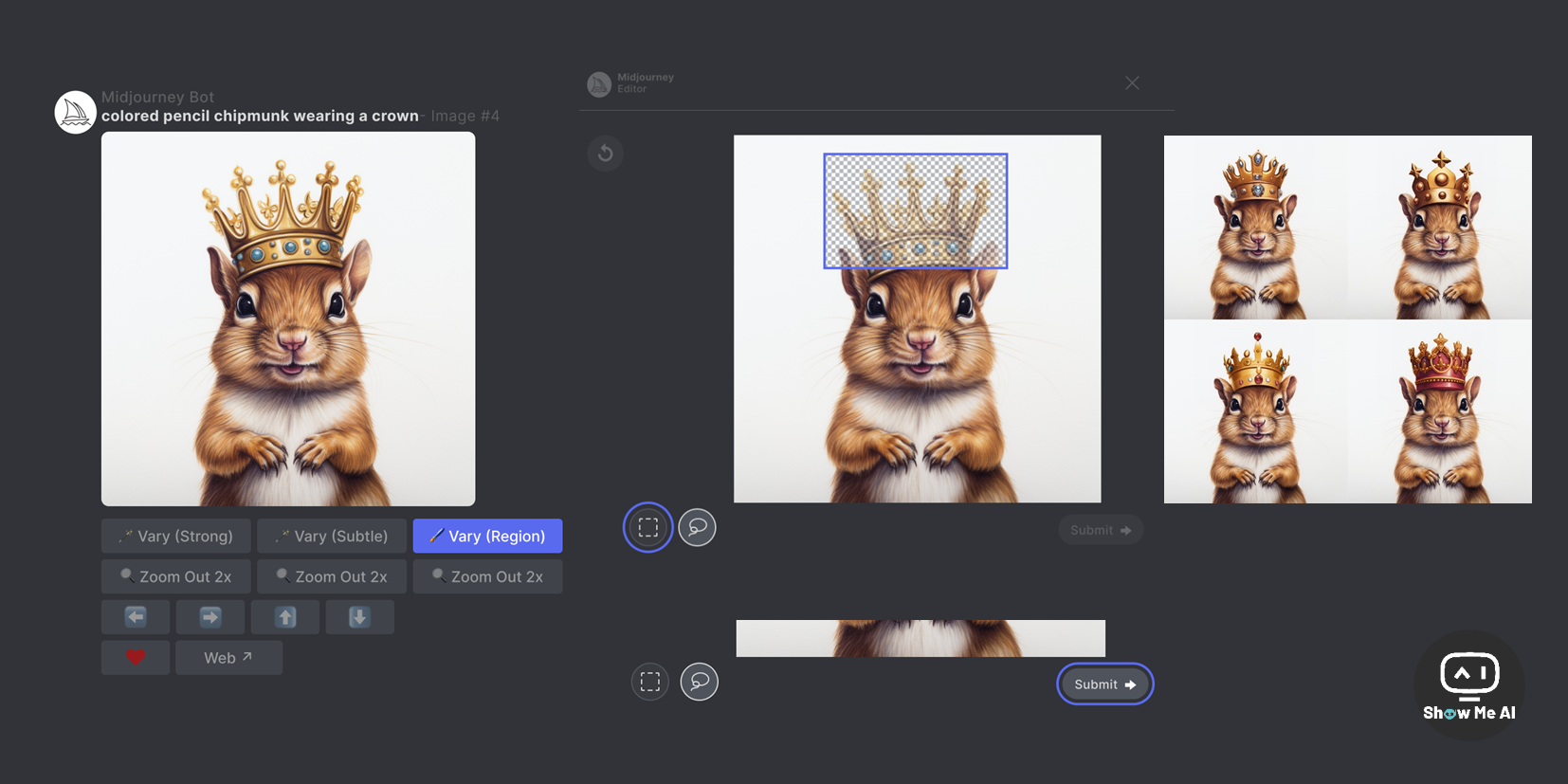
8月22日,Midjourney 正式上线了局部重绘功能,官方称之为 「Vary (Region)」,允许对生成图像的选定区域进行选择,并重新输入 Prompt 进行重新绘制,以下是操作步骤:
使用
/imagine命令创建图像点击 U 按钮放大选定图像
点击 Vary (Region) 按钮,打开编辑界面
选择要重新生成的图像区域
提交并查看结果 ⋙ Midjourney文档 | 6000字使用指南

🤖 首次公开!讯飞星火认知大模型的官方使用报告

讯飞官方最近发出了一份完整的「星火使用报告」,完整地展示了星火大模型地用户群体特性,包括性别/年龄/地域分布、行业分布、兴趣爱好、使用场景,以及7000+助手和高频应用行业。
ShowMeAI 日报选取了其中4条,完整版可以查看原文:
星火大模型的用户大多从事互联网、科研、教育、市场媒体等行业,资深职场经验人士为主,其中有30%以上用户是IT互联网工作者,他们是最擅长利用先进生产力工具的群体之一
星火用户刚需使用场景TOP榜单:知识问答、内容生成、教育学习、编程辅助、生活常识
每100次和星火的对话中就有1句是咨询情感问题的,比如在毕业季,2.68% 的用户选择向星火咨询高考经验、志愿填报等问题
办公场景对于星火大模型的使用需求是最旺盛的,其中排名前10的是:PPT大纲助手、创意商业文案、周报小助理、数学解题助手、市场分析师、短视频脚本助手、产品经理助手、述职小能手、讯飞智聘模拟面试、扩写助手 ⋙ 科大讯飞

🤖 大语言模型 (LLM) 当前的10个主要研究方向和挑战

这是 @Chip Huyen 的一篇博文,将其与工业界、学术界多人的交谈进行了梳理,并总结了10个大语言模型的主要研究方向,或者说公开挑战:
减少并评估输出输出 (虚构信息) Reduce and measure hallucinations:开发对比学习等方法减少LLM的生成虚构信息,建立自检模型等工具检测幻觉,评估模型可靠性;还需设计新指标全面测量不同类型的幻觉
优化上下文长度和上下文构建 Optimize context length and context construction:调研显示大部分问题需依赖上下文解析,所以需要优化上下文长度,提高中间内容的利用效率,并研究 prompt engineering 来更好地构建上下文
融合其他数据形式 Incorporate other data modalities:多模态数据可显著提升模型的理解和泛化能力,在医疗、零售等领域应用广泛;目前多聚焦模型建设,需加强对多模态交互界面优化的研究
提升语言模型的速度和成本效益 Make LLMs faster and cheaper:持续探索模型压缩、量化等技术,优化模型在现有硬件上的部署效率,使大模型实用性更强;社区已取得显著进展,但仍有提升空间
设计新的模型架构 Design a new model architecture:Transformer已优化多年,需要探索新的更高效架构来实现突破,如带内注意力等机制;这需要考虑模型计算复杂度和目标硬件的匹配
开发替代GPU的解决方案 Develop GPU alternatives:GPU已主导多年,需要开发光子芯片等新硬件来实现性能突破,大公司和创业团队正在这方面大力投入研发
提升代理 (人工智能) 的可用性 Make agents usable:探索增强代理模型的可靠性,使其能安全执行各种实际任务,目前仍存在很大挑战;增强社会仿真也是一个应用方向
改进从人类偏好中学习的能力 Improve learning from human preference:现有倾向性学习存在局限,需要在偏好表达、偏好定义、数据采集等方面开展深入研究,以更好地学习人类价值观
提高聊天界面的效率 Improve the efficiency of the chat interface:聊天界面存在局限,需要探索支持多轮多模态交互、无缝结合工作流等方式,来实现更高效的人机协作
构建用于非英语语言的语言模型 Build LLMs for non-English languages:面向低资源语言,需要开发适配技术、构建高质量数据集,来训练非英语语言模型;这也关系到语言学习和文化传播 ⋙ 阅读原文 | 中文翻译版

🤖 对谈 Dify 创始人张路宇:这个男人帮 5 万个 AI 应用接上了大模型

Dify.AI 创始人 & CEO 张路宇受邀在 42 章经播客上与曲凯老师进行了一次深度对话,围绕大型语言模型的能力和应用,让更多人了解大模型投产的现状、潜力和挑战,以及 LLM 中间件的价值。****
只看播客的时间轴就可以感受到,这是一期「相当炸裂」的对谈,从 Dify 话题切入了解两位关于大模型技术、应用和前景的无限畅想。
实际上,ShowMeAI 推荐收听 @42章经 在小宇宙的每!一!期! 播客,并推荐关注 Dify 近期疯狂的各种撒福利活动~
▢ 00:34 什么是 LLMops ?
▢ 07:07 大模型工程化的三种方式:Prompt、Embedding、Fine Tune
▢ 15:48 Agent 的三种形式与面临的三大问题
▢ 23:20 Prompt 的潜力被低估了,它的难度也被低估了
▢ 31:17 未来大模型的市场格局
▢ 33:07 Llama2 离真正投产还有相当长的距离
▢ 38:55 天天提 LangChain,到底什么是 LangChain?
▢ 48:23 Dify 五万多个应用中,最典型的落地场景是?
▢ 51:57 未来个人助手的入口会在哪儿?
▢ 53:48 日后的微信通讯录里躺着的可能是一群 bot
▢ 55:07 AI 的三大发展方向:请大模型看 4D 电影、模型小型化、一切数据向量化
▢ 59:07 对于 AI,我俩最焦虑的事情是同一个
▢ 1:02:44 —— 画外音环节 ——
▢ 1:04:35 曲凯会格外喜欢什么样的创业者?
▢ 1:08:49 曲凯怎么看中间层的创业机会?
▢ 1:11:47 现在创业者普遍暴露出来的问题都有什么? ⋙ 小宇宙 @42章经 | 核心话题的文字版

🤖 关于 Llama 2 的一切资源,我们都帮你整理好了
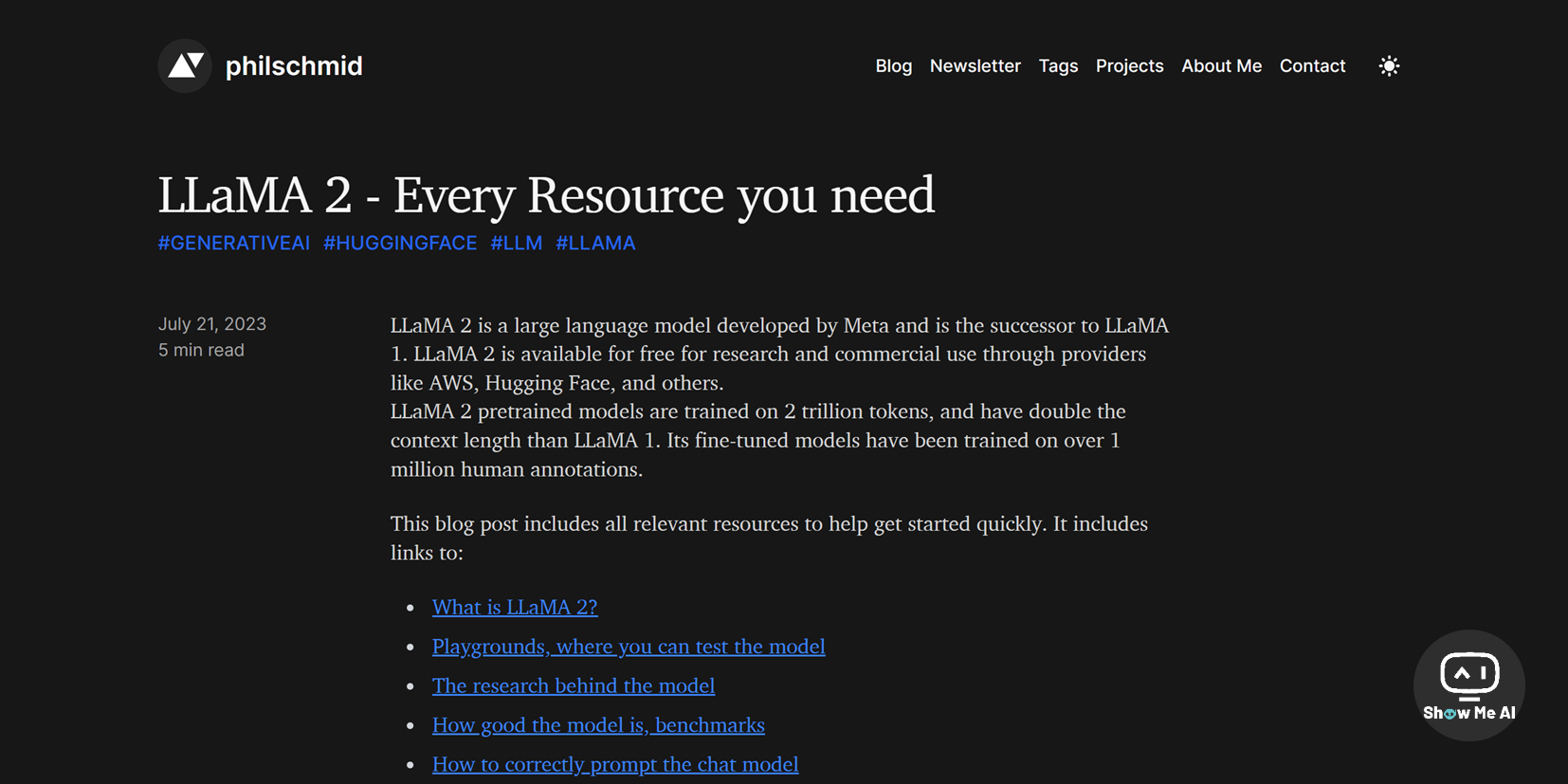
LLaMA 2 是 Meta 最近开源的一个大语言模型,是 LLaMA 1 的升级版本,可以通过AWS、Hugging Face 获取,并且允许自由地用于研究和商业用于。
这篇博客比较全面地梳理了 LLaMA 2 相关的各类资源 & 链接,是一篇非常不错的入门指南:
Llama 2 是什么:Llama 2 是 Meta 发布的新的开源大型语言模型,提供了7B、13B和70B三种规模的模型,与 LLaMA 1 相比最大程度提高了视野长度
即刻解锁 Llama2:文章汇总了几个支持测试的 playground,包括HuggingChat、Hugging Face Spaces、Perplexity
Llama 2 背后的研究工作:对于 Llama 2 的研究过程感兴趣的话,作者给出了几项学习资料,包括论文、视频、文章链接
Llama 2 的性能有多好, 基准测试:Llama 2 在推理、编程、知识测验等多个基准测试上优于其他开源语言模型,相关资源包括开源大语言模型排行榜、Meta公告等
如何为 LLaMA 2 Chat 写提示词 (prompts) :想与 Llama 2 Chat 进行高效地交互则需要你提供合适的提示词,文章给出了单轮、多轮对话的提示词模板
如何训练 LLaMA 2:文章提供了关于指令微调、PEFT技术微调等相关资源,帮助训练你自己版本的 LLaMA 2
如何部署 Llama 2:文章给出了各种部署方式的教程,包括本地部署、使用托管服务如 Hugging Face Inference Endpoints 或通过 AWS、Google Cloud、Microsoft Azure 等 ⋙ 阅读原文 @Philipp Schmid | 中文翻译版本 @Hugging Face
🤖 普林斯顿大学 COS 597G (Fall 2022) 课程,带你理解大语言模型

「COS 597G: Understanding Large Language Models」是普林斯顿大学2022年秋季开设的一门研究生课程,由 Danqi Chen 教授主讲,Alexander Wettig 担任助教。
课程目标是让学生了解大语言模型的相关前沿研究话题,包括技术基础、前沿话题、微调、系统设计、安全性和伦理问题等,需有机器学习和自然语言处理背景。通过课程学习,学生可以掌握大语言模型领域的前沿研究和手段。
注意!课程页面 Schedule 中对每个话题给出了大量的推荐阅读资料,并给出了完整的 Slides!
导言 (Introduction)
编码器模型 (BERT)
编码器-解码器模型 (T5)
解码器模型 (GPT-3)
小样本学习提示方法 (Prompting for few-shot learning)
高效提示调参 (Prompting as parameter-efficient fine-tuning)
上下文学习 (In-context learning)
语言模型提示校准 (Calibration of prompting LLMs)
推理 (Reasoning)
知识 (Knowledge)
数据 (Data)
模型扩大 (Scaling)
隐私 (Privacy)
评估偏见和有害内容 (Bias & Toxicity I: evaluation)
缓解偏见和有害内容 (Bias & Toxicity II: mitigation)
稀疏模型 (Sparse models)
检索增强语言模型 (Retrieval-based LMs)
人类反馈训练语言模型 (Training LMs with human feedback)
代码语言模型 (Code LMs)
多模态语言模型 (Multimodal LMs)
AI对齐 (AI Alignment) ⋙ 普林斯顿大学 COS 597G (Fall 2022)
感谢贡献一手资讯、资料与使用体验的 ShowMeAI 社区同学们!

◉ 点击 👀日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
◉ 点击 🎡生产力工具与行业应用大全,一起在信息浪潮里扑腾起来吧!